
Ogólnodostępne zbiory danych do Machine Learningu
Tak się składa, że dane i odpowiedzi jakie chcemy z nich wyciągnąć, to dwie najważniejsze rzeczy, które każdy specjalista od ML (zwany data scientist) musi posiadać, aby móc wykonywać swoją pracę. W tym wpisie przygotowałem krótki przewodnik po najpopularniejszych otwartych i ciekawych zbiorach danych.
Na początku zdefiniujemy sobie co oznacza pojęcie „zbiór danych„:
Zbiór danych to kolekcja danych statystycznych zwykle ujętych w formie stabelaryzowanej.
Najczęściej kolumny odpowiadają obserwowanym cechom statystycznym a każdy wiersz opisuje jedną obserwację z próby. Wartości komórek macierzy opisują realizacje danych zmiennych w kolejnych obserwacjach. (źródło: Wikipedia)
Ok, skoro dane będą najczęściej ujęte w tabelach, to powinny z reguły być dostępne pod postacią plików CSV, które idealnie się do tego nadają. Większość przedstawionych tu zbiorów to właśnie pliki tekstowe, w których poszczególne atrybuty oddzielone są przecinkiem. W ten sposób bardzo łatwo możemy zaimportować je w każdym języku programowania.
Zacznijmy nasz przegląd od najpopularniejszego zestawu wszech czasów:
Iris Data Set
Zestaw pomiarów kwiatów irysa, udostępniony po raz pierwszy przez Ronalda Fishera w roku 1936. Jeden z najbardziej znanych zbiorów, a zarazem bardzo prosty i użyteczny. Celem jest wytrenowanie systemu, który na podstawie 4 podanych parametrów, poda właściwą klasę kwiatu (jedną z trzech dostępnych).
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 150 | 5 | nie | klasyfikacja |
Link do zbioru: https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
Zbiór irysów składa się z 4 wartości pomiarów jego płatków (szerokości i długość) oraz klasy do jakiej należy. Przykład kilku wybranych rekordów:
sepal length,sepal width,petal length,petal width,class
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
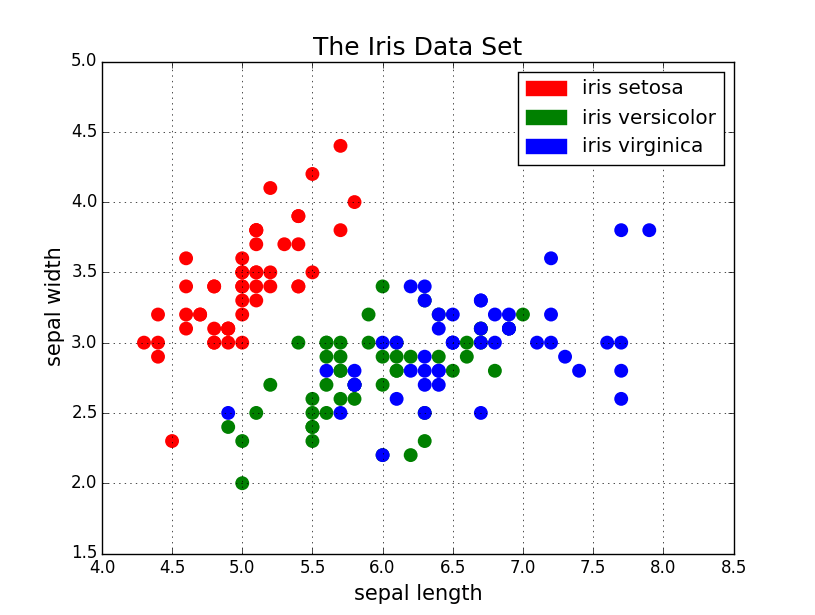
6.3,2.9,5.6,1.8,Iris-virginicacsPrzykładowa wizualizacja zbioru z podziałem na klasy:
Abalone Data Set
 Zbiór różnych parametrów słuchotek (uchowców) – ślimaków morskich. Ustalenie wieku takiego ślimaka możliwe jest dopiero po rozcięciu jego muszli i zbadaniu pod mikroskopem ilości pierścieni. To zadanie jest bardzo żmudne i czasochłonne dlatego poszukuje się innych skutecznych metod. Przeznaczeniem tego zbioru to stworzenie systemu, który na podstawie zadanych parametrów, zwróci poprawny wiek słuchotki.
Zbiór różnych parametrów słuchotek (uchowców) – ślimaków morskich. Ustalenie wieku takiego ślimaka możliwe jest dopiero po rozcięciu jego muszli i zbadaniu pod mikroskopem ilości pierścieni. To zadanie jest bardzo żmudne i czasochłonne dlatego poszukuje się innych skutecznych metod. Przeznaczeniem tego zbioru to stworzenie systemu, który na podstawie zadanych parametrów, zwróci poprawny wiek słuchotki.
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 4177 | 9 | nie | regresja |
Link do zbioru: http://www.cs.toronto.edu/~delve/data/abalone/desc.html
Dostępne atrybuty i przykładowe dane:
Name Data Type Meas. Description
---- --------- ----- -----------
Sex nominal M, F, and I (infant)
Length continuous mm Longest shell measurement
Diameter continuous mm perpendicular to length
Height continuous mm with meat in shell
Whole weight continuous grams whole abalone
Shucked weight continuous grams weight of meat
Viscera weight continuous grams gut weight (after bleeding)
Shell weight continuous grams after being dried
Rings integer +1.5 gives the age in years
M,0.455,0.365,0.095,0.514,0.2245,0.101,0.15,15
M,0.35,0.265,0.09,0.2255,0.0995,0.0485,0.07,7
F,0.53,0.42,0.135,0.677,0.2565,0.1415,0.21,9
M,0.44,0.365,0.125,0.516,0.2155,0.114,0.155,10
I,0.33,0.255,0.08,0.205,0.0895,0.0395,0.055,7
Adult Data Set (aka Census Income)
Duża kolekcja danych o osobach dorosłych, której celem jest przewidzenie, czy zarobki danej osoby przekroczą 50 tys dolarów rocznie. Zbiór ten jest fragmentem prawdziwej bazy Censusa (amerykańskiego spisu ludności). Jego jedyną wadą jest wiek, ponieważ został stworzony na podstawie danych z roku 1994.
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 48842 | 15 | tak (7%) | klasyfikacja |
Link do zbioru: http://www.cs.toronto.edu/~delve/data/adult/desc.html
Dostępne atrybuty i przykład danych:
age: continuous.
workclass: Private, Self-emp-not-inc, Self-emp-inc, Federal-gov, Local-gov, State-gov, Without-pay, Never-worked.
fnlwgt: continuous.
education: Bachelors, Some-college, 11th, HS-grad, Prof-school, Assoc-acdm, Assoc-voc, 9th, 7th-8th, 12th, Masters, 1st-4th, 10th, Doctorate, 5th-6th, Preschool.
education-num: continuous.
marital-status: Married-civ-spouse, Divorced, Never-married, Separated, Widowed, Married-spouse-absent, Married-AF-spouse.
occupation: Tech-support, Craft-repair, Other-service, Sales, Exec-managerial, Prof-specialty, Handlers-cleaners, Machine-op-inspct, Adm-clerical, Farming-fishing, Transport-moving, Priv-house-serv, Protective-serv, Armed-Forces.
relationship: Wife, Own-child, Husband, Not-in-family, Other-relative, Unmarried.
race: White, Asian-Pac-Islander, Amer-Indian-Eskimo, Other, Black.
sex: Female, Male.
capital-gain: continuous.
capital-loss: continuous.
hours-per-week: continuous.
native-country: United-States, Cambodia, England, Puerto-Rico, Canada, Germany, Outlying-US(Guam-USVI-etc), India, Japan, Greece, South, China, Cuba, Iran, Honduras, Philippines, Italy, Poland, Jamaica, Vietnam, Mexico, Portugal, Ireland, France, Dominican-Republic, Laos, Ecuador, Taiwan, Haiti, Columbia, Hungary, Guatemala, Nicaragua, Scotland, Thailand, Yugoslavia, El-Salvador, Trinadad&Tobago, Peru, Hong, Holand-Netherlands.
class: >50K, <=50K
39, State-gov, 77516, Bachelors, 13, Never-married, Adm-clerical, Not-in-family, White, Male, 2174, 0, 40, United-States, <=50K
50, Self-emp-not-inc, 83311, Bachelors, 13, Married-civ-spouse, Exec-managerial, Husband, White, Male, 0, 0, 13, United-States, <=50K
38, Private, 215646, HS-grad, 9, Divorced, Handlers-cleaners, Not-in-family, White, Male, 0, 0, 40, United-States, <=50K
53, Private, 234721, 11th, 7, Married-civ-spouse, Handlers-cleaners, Husband, Black, Male, 0, 0, 40, United-States, <=50K
28, Private, 338409, Bachelors, 13, Married-civ-spouse, Prof-specialty, Wife, Black, Female, 0, 0, 40, Cuba, <=50K
37, Private, 284582, Masters, 14, Married-civ-spouse, Exec-managerial, Wife, White, Female, 0, 0, 40, United-States, <=50K
49, Private, 160187, 9th, 5, Married-spouse-absent, Other-service, Not-in-family, Black, Female, 0, 0, 16, Jamaica, <=50K
Heart Disease Data Set
Zbiór różnych danych pacjentów i informacji na temat ich problemów z sercem. Został stworzony przy współpracy 4 różnych instytucji z 3 różnych krajów. Zestaw ten posiada dużą liczbę atrybutów, ale najczęściej stosuje się 14 wybranych. Każdy pacjent otrzymał liczbową klasę od 0 (brak schorzeń) do 4, która określa jego problemy sercowe lub ich brak. Celem jest stworzenie systemu, który na podstawie danych wejściowych, zadeklaruje czy pacjent posiada jakiś problem z sercem czy nie.
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 303 | 75 | tak | klasyfikacja |
Link do zbioru: https://archive.ics.uci.edu/ml/machine-learning-databases/heart-disease/
Przykład 14 wybranych atrybutów i ich wartości:
1. #3 (age)
2. #4 (sex)
3. #9 (cp)
4. #10 (trestbps)
5. #12 (chol)
6. #16 (fbs)
7. #19 (restecg)
8. #32 (thalach)
9. #38 (exang)
10. #40 (oldpeak)
11. #41 (slope)
12. #44 (ca)
13. #51 (thal)
14. #58 (num) (the predicted attribute)
63.0,1.0,1.0,145.0,233.0,1.0,2.0,150.0,0.0,2.3,3.0,0.0,6.0,0
67.0,1.0,4.0,160.0,286.0,0.0,2.0,108.0,1.0,1.5,2.0,3.0,3.0,2
67.0,1.0,4.0,120.0,229.0,0.0,2.0,129.0,1.0,2.6,2.0,2.0,7.0,1
37.0,1.0,3.0,130.0,250.0,0.0,0.0,187.0,0.0,3.5,3.0,0.0,3.0,0
41.0,0.0,2.0,130.0,204.0,0.0,2.0,172.0,0.0,1.4,1.0,0.0,3.0,0
56.0,1.0,2.0,120.0,236.0,0.0,0.0,178.0,0.0,0.8,1.0,0.0,3.0,0
MNIST database
Dobrze znany zestaw odręcznie napisanych cyfr (od 0 do 9). Celem jest oczywiście rozpoznanie jaka cyfra znajduje się na obrazku. Zestaw ten jest bardzo popularny i służy do sprawdzania wydajności i skuteczności różnych algorytmów uczących się. Jest wykorzystywany w licznych pracach naukowych i opracowaniach. Możecie również natknąć się na różne jego wariacje (np. notMNIST).
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 60 000 + 10 000 | 28×28 pikseli | nie | klasyfikacja |
Link do zbioru: http://yann.lecun.com/exdb/mnist/
Przykład dla cyfry 6:

Labeled Faces in the Wild
Zestaw zdjęć twarzy ludzkich. Został stworzony przez University of Massachusetts w celu swobodnego rozpoznawania twarzy ludzkich. Wybrane twarze pojawiają się w zbiorze więcej niż jeden raz. To powoduje, że możemy wyodrębnić tutaj dwa cele. Pierwszy to rozpoznanie twarzy na dowolnym zdjęciu. Drugi to wyszukanie twarzy powtarzających się (należących do tej samej osoby). Na stronie projektu znajdują się linki do licznych opracowań i rezultatów badań.
| Ilość próbek | Ilość atrybutów | Brakujące wartości | Problem |
| 13233 | 250×250 pikseli | nie | klasyfikacja |
Link do zbioru: http://vis-www.cs.umass.edu/lfw/
Przykład:

Podsumowanie
Przedstawiłem kilka ciekawych zbiorów, które mogą służyć do nauki Machine Learningu. Gdyby jednak ktoś chciałby więcej, to w internecie znajdzie pokaźną liczbę zestawów łącznie z ich opracowaniami. Szczególnie polecam jedną stronę, na której znajdziecie nie tylko nowe zbiory, ale również ciekawe wyzwania, których rozwiązanie może powiększyć saldo waszego konta lub dostarczyć Wam nową posadę: https://www.kaggle.com/
Entuzjasta programowania. Z zawodu web developer. Pragmatyk. Od jakiegoś czasu również przedsiębiorca. Racjonalista. W wolnych chwilach biega i bloguje. Miłośnik gier i grywalizacji. Więcej na jego temat znajdziesz w zakładce „O mnie” tego bloga.



