Wydajne struktury danych w PHP 7
 Najnowsza 7 wersja PHP wniosła bardzo duże usprawnienia pod kątem wydajności. Jedną z przyczyn była nowa implementacja tablic. Pomimo tego, zmiennie w PHP (ze względu na luźne typowanie) dalej nie są zbyt wydajnie i istnieje przestrzeń do poprawy. Tak się składa, że jeden z pasjonatów postanowił coś z tym zrobić. Przedstawiam omówienie najnowszego rozszerzenia dla PHP 7 o nazwie „ds” (data structures) autorstwa: Rudi Theunissen (@rudi_theunissen).
Najnowsza 7 wersja PHP wniosła bardzo duże usprawnienia pod kątem wydajności. Jedną z przyczyn była nowa implementacja tablic. Pomimo tego, zmiennie w PHP (ze względu na luźne typowanie) dalej nie są zbyt wydajnie i istnieje przestrzeń do poprawy. Tak się składa, że jeden z pasjonatów postanowił coś z tym zrobić. Przedstawiam omówienie najnowszego rozszerzenia dla PHP 7 o nazwie „ds” (data structures) autorstwa: Rudi Theunissen (@rudi_theunissen).
Inspiracją dla tego wpisu był dla mnie sam autor. Patrząc na repo (php-ds/ds) i ilość testów jednostkowych, nie da się przejść obojętnie. Całe rozszerzenie zostało naprawdę dobrze zrobione przez prawdziwego pasjonata programowania. Generalnie można zazdrościć 🙂 Przejdźmy do konkretów:
Strona projektu: https://github.com/php-ds/ds
Namespace rozszerzenia: Ds\
Zaczniemy od omówienia nowych interfejsów.
Collection
Collection jest bazowym interfejsem dla wszystkich nowych struktur. Umożliwia on używanie nowych typów w metodach takich jak: foreach, echo, count, print_r, var_dump, serialize, json_encode, i clone. Czyli podstawowe zachowanie tablic (interfejsy: Traversable, Iterator, ArrayAccess itp.). Dodatkowo wprowadza parę nowych metod: clear, copy, count, isEmpty i toArray.
Sequence
Sequence służy do opisania struktury która przechowuje wartości w liniowej przestrzeń. Niektóry języki programowania stosują na to nazwę List. Sekwencja jest bardzo podobna do natywnej tablicy z paroma wyjątkami:
- wartości są zawsze indeksowane za pomocą kolejnych liczb naturalnych (uwzględniając zero): [0, 1, 2, 3 …]
- dodanie lub usunięcie wartości spowoduje przeliczenie indeksów
- dostęp do wartości możliwy jest tylko za pomocą indeksów [0, 1, 2, 3 …]
Hashable
Hashable pozwala aby obiekty mogły być używane jako klucze. Autor pisze, że powstało już parę RFC które miały wprowadzić natywną obsługę „haszowania” obiektów, ale żadne z nich nie przeszły. Jest to dość prosty interfejs z dwoma metodami:
- hash – która powinna zwrócić skalarną wartość (hasz danego obiektu)
- equals – powinna zwrócić true gdy obiekt jest identyczny (lub zwraca identyczny hash)
Typy które uwzględniają nowy interfejs to Map i Set.
Teraz czas na nowe struktury:
Vector
Vector implementuje interfejs Sequence i jest ciągłą strukturą, która powiększa i pomniejsza się automatycznie. Wektor jest najbardziej efektywną strukturą (pod kątem pamięci) ponieważ mapuje bezpośrednio klucze do wartości bez zbędnych funkcjonalności. Benchmarki i porównania wydajności struktur zamieszczone są na samym dole wpisu.
use Ds\Vector;
$vector = new Vector();
$vector->push('A');
$vector->push('B');
$vector->get(1);
$vector->set(1, 'C');
$vector->pop();
Autor utworzył nawet krótkie animacje przedstawiające zasady działania wybranych typów. Poniżej sposób zachowania typu Vector:
Plusy:
- bardzo niskie zużycie pamięci
- bardzo szybkie iteracje
- get, set, push, pop, shift, i unshift mają złożoność O(1)
Minusy:
- insert, remove, shift, i unshift mają złożoność O(n)
The number one data structure used in Photoshop was Vectors.
Sean Parent, CppCon 2015
Deque
Podobnie jak Vector, Deque również implementuje Sequence i tak samo w sposób ciągły przechowuje wartości automatycznie regulując zajmowaną powierzchnię. Posiada on jednak dwa wskaźniki: head i tail. Dzięki temu może on niejako zawijać swój koniec co pozwala oszczędzi czynności robienia miejsca nowym wartością. Bardzo dobrze widać to na poniższej animacji:
Zawijanie wartości ma jednak pewne konsekwencje. Aby otrzymać wartość na konkretnym indeksie trzeba dokonać niezbędnych obliczeń ((head + position) % capacity).
use Ds\Deque;
$deque = new Deque();
$deque->push('C');
$deque->push('D');
$deque->unshift('B');
$deque->unshift('A');
$deque->pop(); // return D
$deque->shift(); // return APlusy:
- bardzo małe zużycie pamięci
- get, set, push, pop, shift, i unshift mają złożoność O(1)
Minusy:
- insert, remove mają złożoność O(n)
- pojemność bufora musi być potęgą liczby 2.
Stack
Stack to kolejka typu LIFO – last in, first out (ostatni na wejściu, pierwszy na wyjściu). Jej elementy można dokładać/usuwać tylko i wyłącznie w ten sposób (czyli nie możemy zwyczajnie iterować po każdym elemencie). Aby sięgnąć po jakąś wartość trzeba ściągać z naszego stosu elementy ostatnio do niego dołożone. Stack wewnętrznie został zaimplementowany na podstawie typu Vector.
use Ds\Stack;
$stack = new Stack();
$stack->push('A');
$stack->push('B');
$stack->push('C');
$stack->count(); // return 3
$stack->pop(); // return C
$stack->pop(); // return B
$stack->pop(); // return A
$stack->isEmpty(); // return truePlusy:
- analogicznie jak Vector
- zabezpiecza kolejność danych
- uniemożliwia podejrzenie wartości bez jej pobrania
Minusy:
- analogicznie jak Vector
Queue
Przeciwieństwo Stack. Queue to standardowa kolejka FIFO – first in, first out (pierwszy na wejściu, pierwszy na wyjściu). Całość zaimplementowana tak samo Stack – czyli za pomocą Vector. W ten sposób plusy i minusy są analogicznie.
use Ds\Queue;
$queue = new Queue();
$queue->push('A');
$queue->push('B');
$queue->push('C');
$queue->count(); // return 3
$queue->pop(); // return A
$queue->pop(); // return B
$queue->pop(); // return C
$queue->isEmpty(); // return true
PriorityQueue
Bardziej ciekawsza odmiana Queue. Jest to również FIFO ale z możliwością nadawania priorytetów (int). Wartości z najwyższym priorytetem będą ustawiać się na początek kolejki i schodzić z niej jako pierwsze. Wartości z takim samym priorytetem będą ustawiać się jak w zwykłej kolejce Queue.
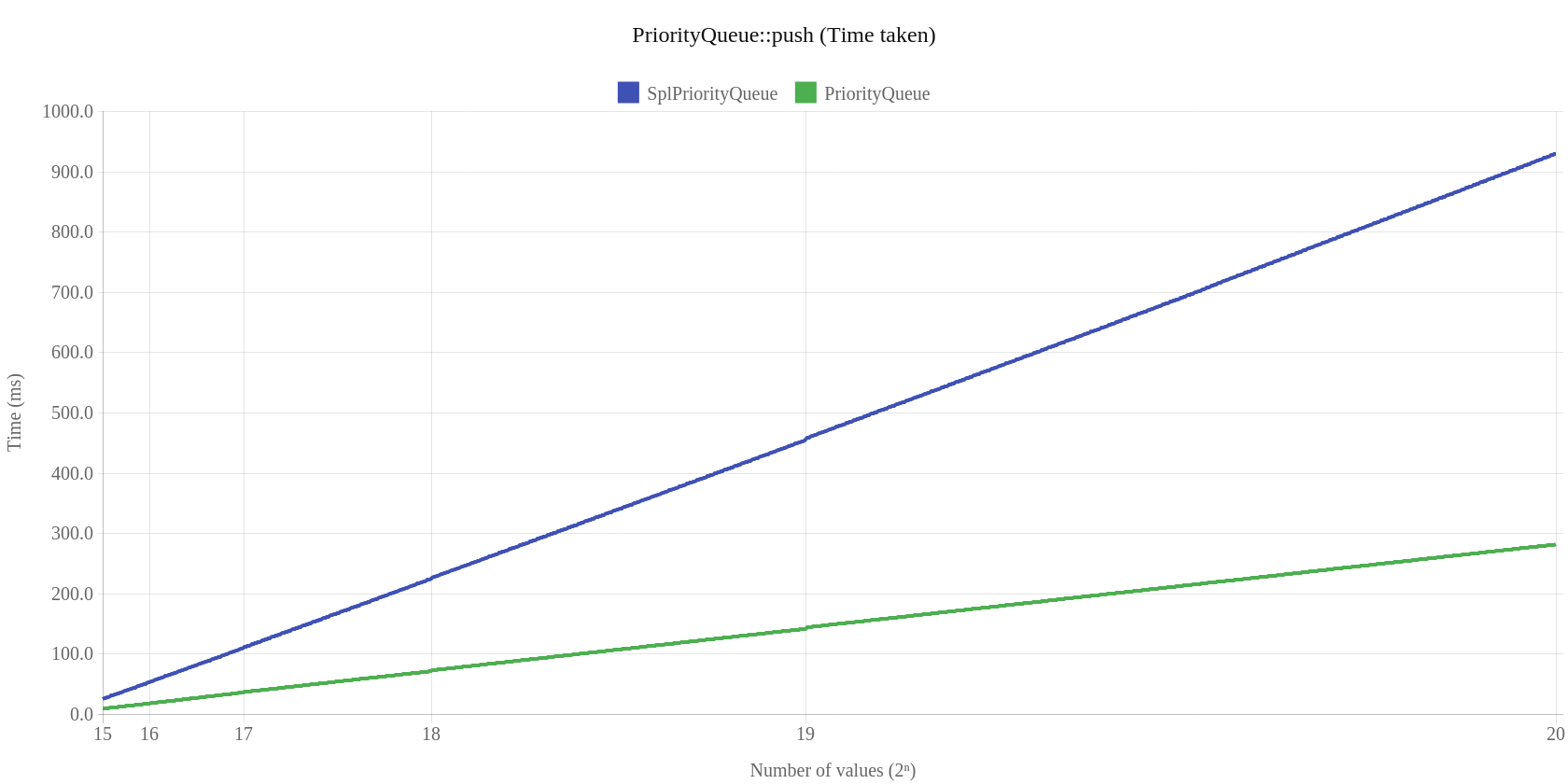
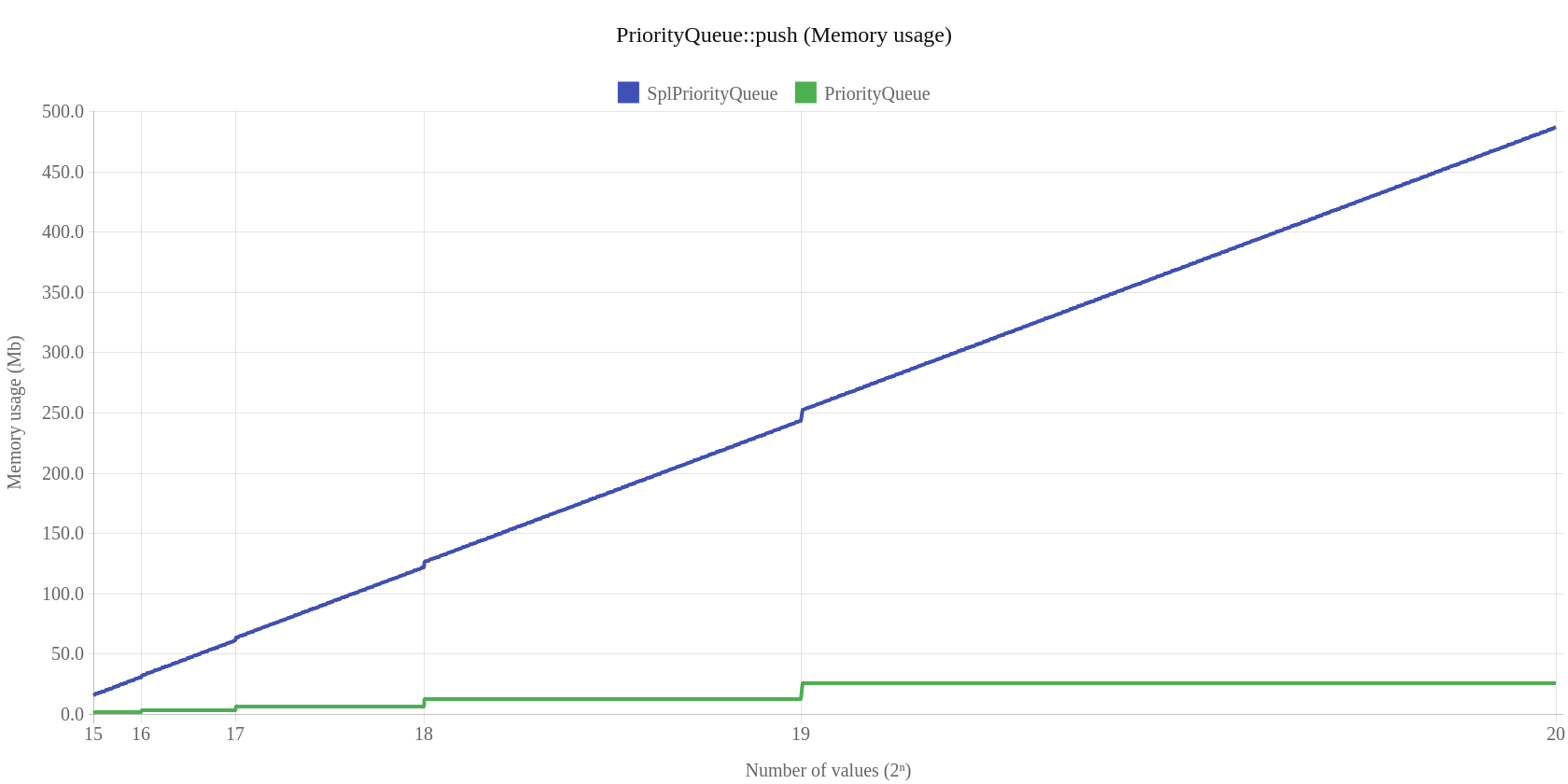
Autor pokazuje (co będzie widać później w benchmarkach), że jego implementacja PriorityQueue w porównaniu do SplPriorityQueue (bardziej oficjalna implementacja) jest lepsza ponieważ:
- jest dwukrotnie szybsza
- wykorzystuje dwudziestokrotnie mniej pamięci (tylko 5%)
use Ds\PriorityQueue;
$queue = new PriorityQueue();
$queue->push('A', 1);
$queue->push('B', 1);
$queue->push('C', 5);
$queue->push('D', 5);
$queue->pop(); // return C
$queue->pop(); // return D
$queue->pop(); // return A
$queue->pop(); // return B
$queue->isEmpty(); // return true
Map
Map to prosta kolekcja typu klucz – wartość. Prawie identyczna jak natywny array, ale kluczem może być wszystko, np. obiekt (o ile jest unikalny).
use Ds\Map;
$map = new Map();
$map->put('name', 'John');
$map->get('name'); // return John
$map->put($object, $value);
$map->get($object); // return $value
$map->containsKey($object); // return true
Plusy:
- wydajność i zużycie pamięci analogicznie jak w array
- automatycznie zwalnia dostępną pamieć przy usuwania wartości
- klucze mogą być obiektami (interfejs Hashable)
- put, get, remove, i containsKey mają złożoność typu O(1)
Minusy:
- brak możliwości konwersji do array gdy klucze są obiektami
- brak możliwości dostępu po pozycji (indeksie)
Set
Set jest analogiczny jak Map, ale jego wartości muszą być unikalne. Jeżeli dodamy do Seta wartość która już istnieje nie zmieni to jego stanu. Taki sposób przechowywania danych da pewną przewagę w momencie sortowania danych oraz w porównaniu do natywnej funkcji array_unique. Do dyspozycji znowu mamy ciekawą wizualizację:
use Ds\Set;
$set = new Set();
$set->add('A');
$set->add('B');
$set->add('C');
$set->count(); // return 3
$set->add('A');
$set->add('B');
$set->count(); // return 3
Benchmarki
Ok, skoro wiemy już jakie nowe typy danych zostały nam udostępnione, czas przyjrzeć się jak prezentują się one pod kątem wydajnościowym i pamięciowym. Autor udostępnił nam benchmark który generuje bardzo ładne wykresy. Każdy samodzielnie może uruchomić sobie testy i wygenerować wynik (na własnym sprzęcie).
Pierwsze dwa wykresy dotyczą klasy PriorityQueue, która wypada zdecydowanie najlepiej. Zarówno czas jak i pobrana pamięć dla operacji push jest zdecydowanie lepsza od „standardowej” implementacji SplPriorityQueue:
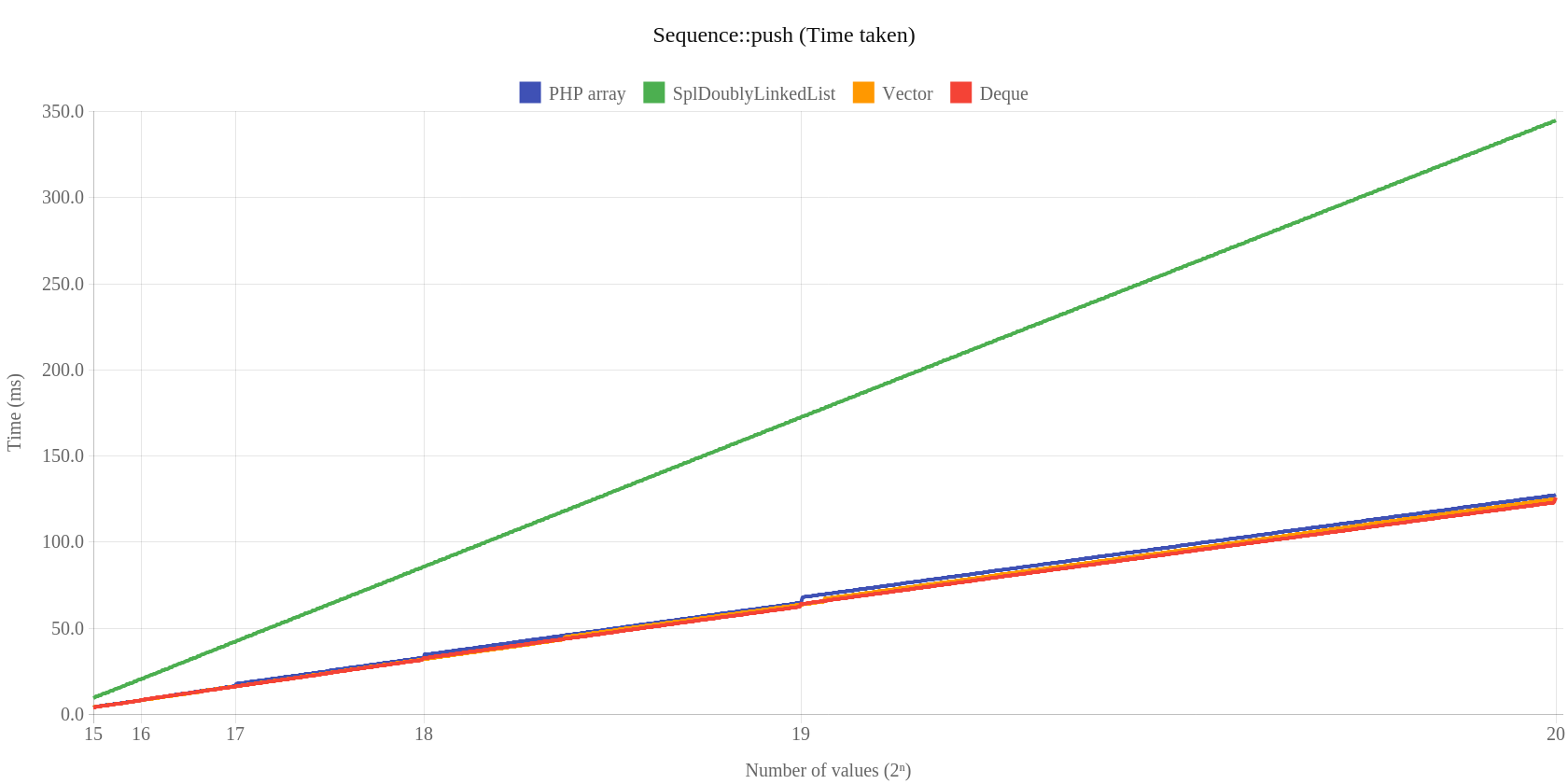
Następnie mamy testy wydajności dla klasy Sequence, która została zastosowana zarówno w Vectore jak i Deque. Czas jak i pamięć jest tutaj zdecydowanie lepsza. Zaczynamy od operacji push:
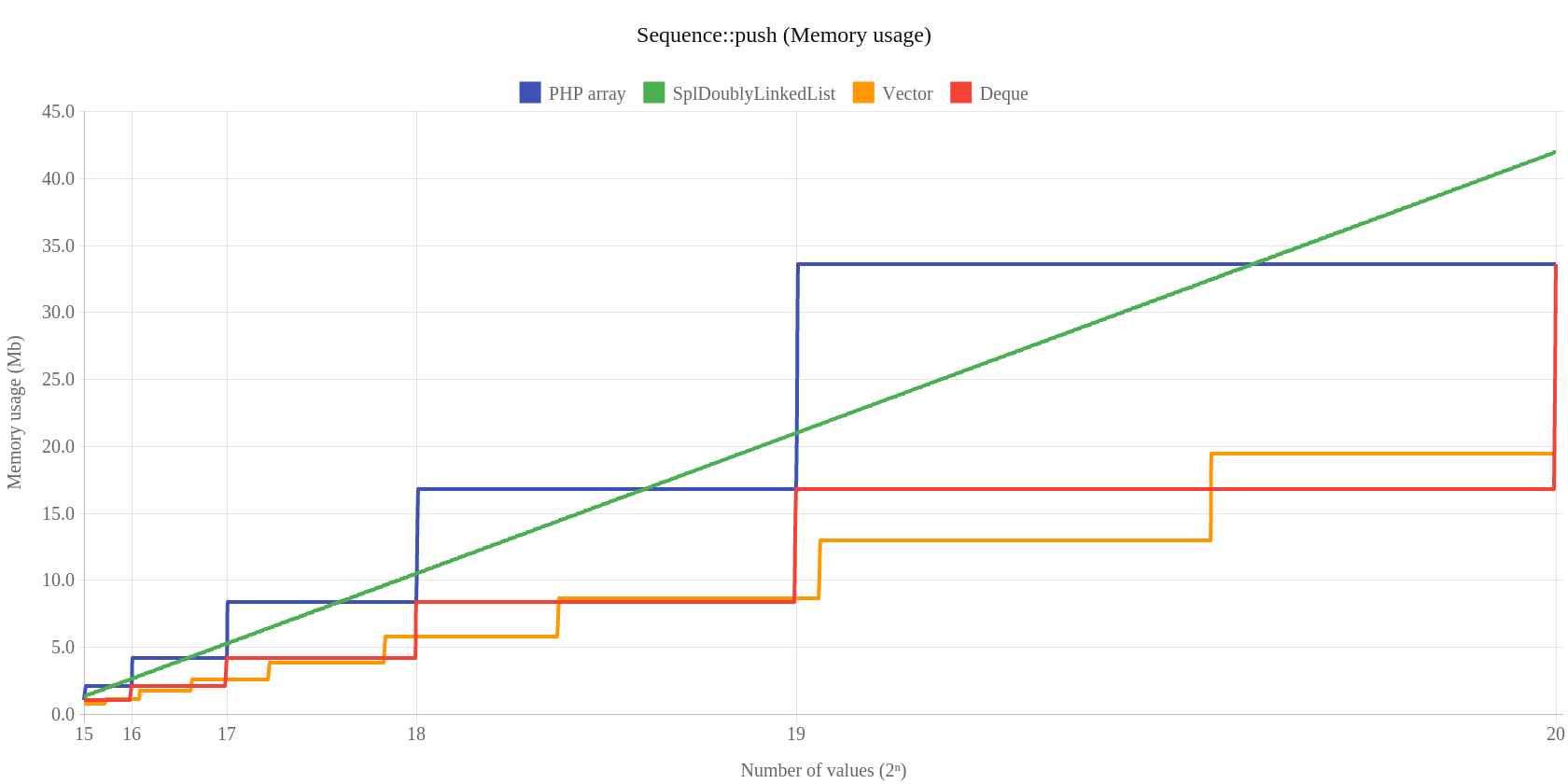
Kolejno unshift:

I wreszcie pop:
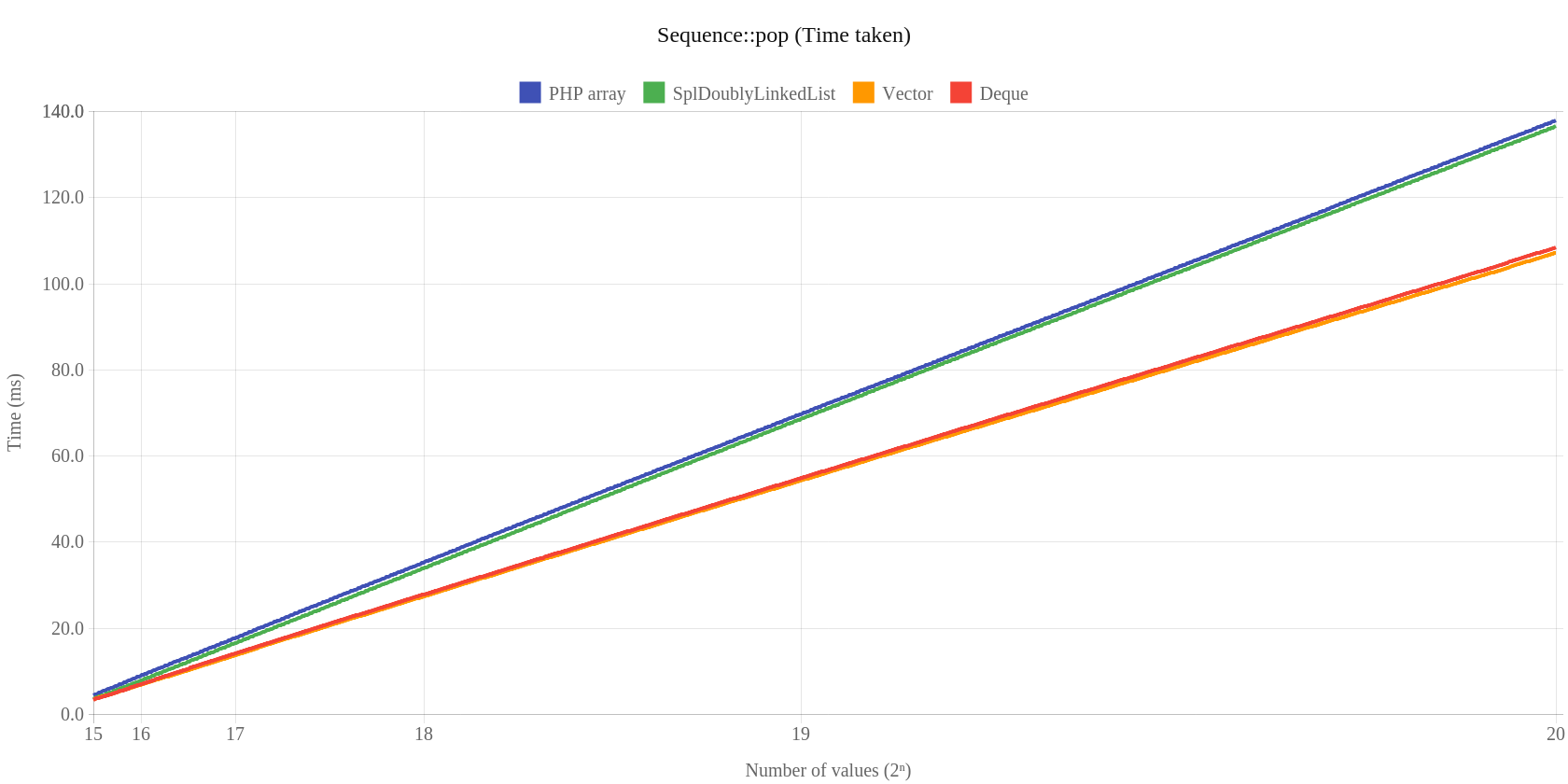
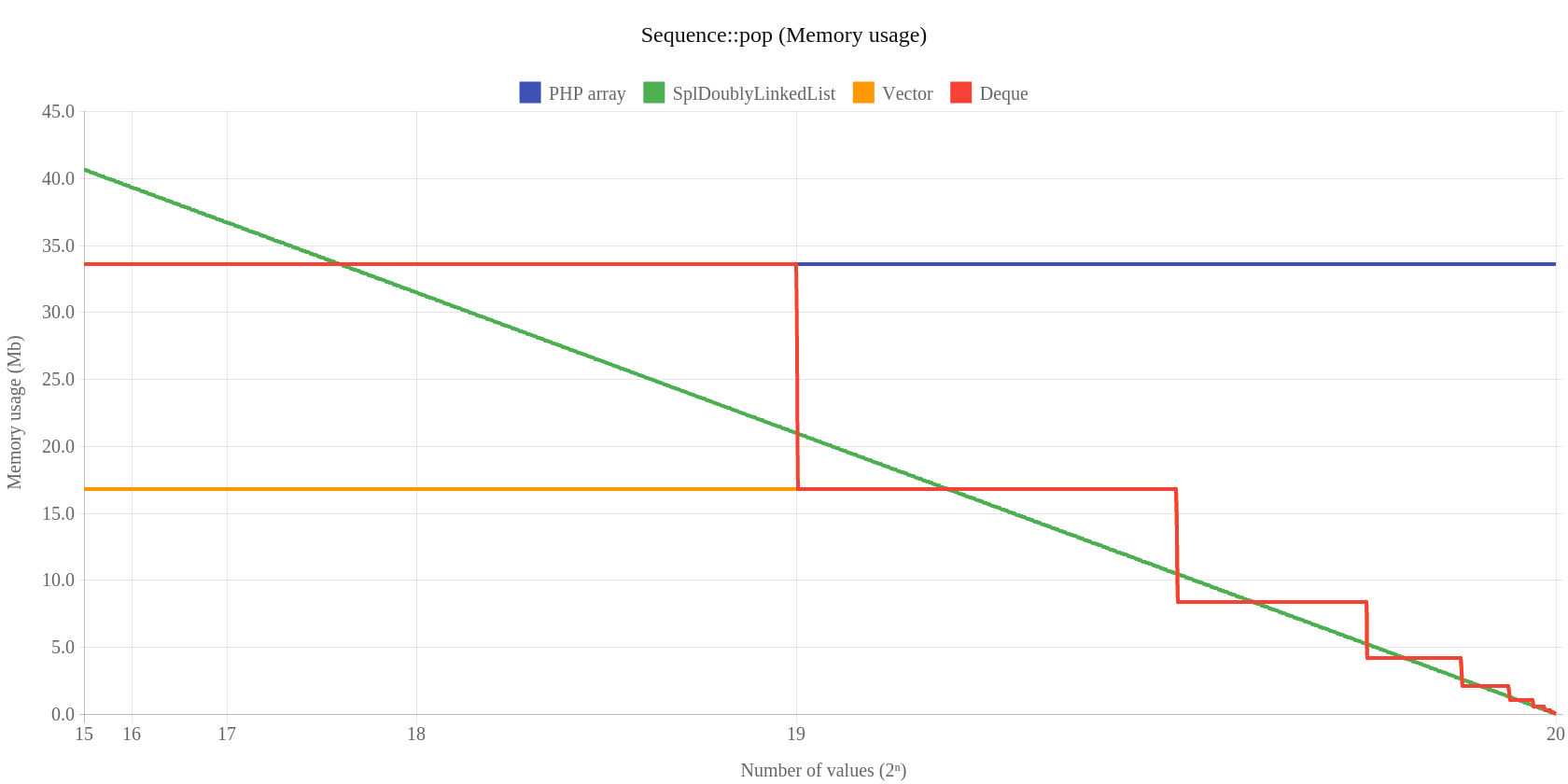
Warto pokazać jeszcze proces zwalniania pamięci dla klasy Map – metoda remove:
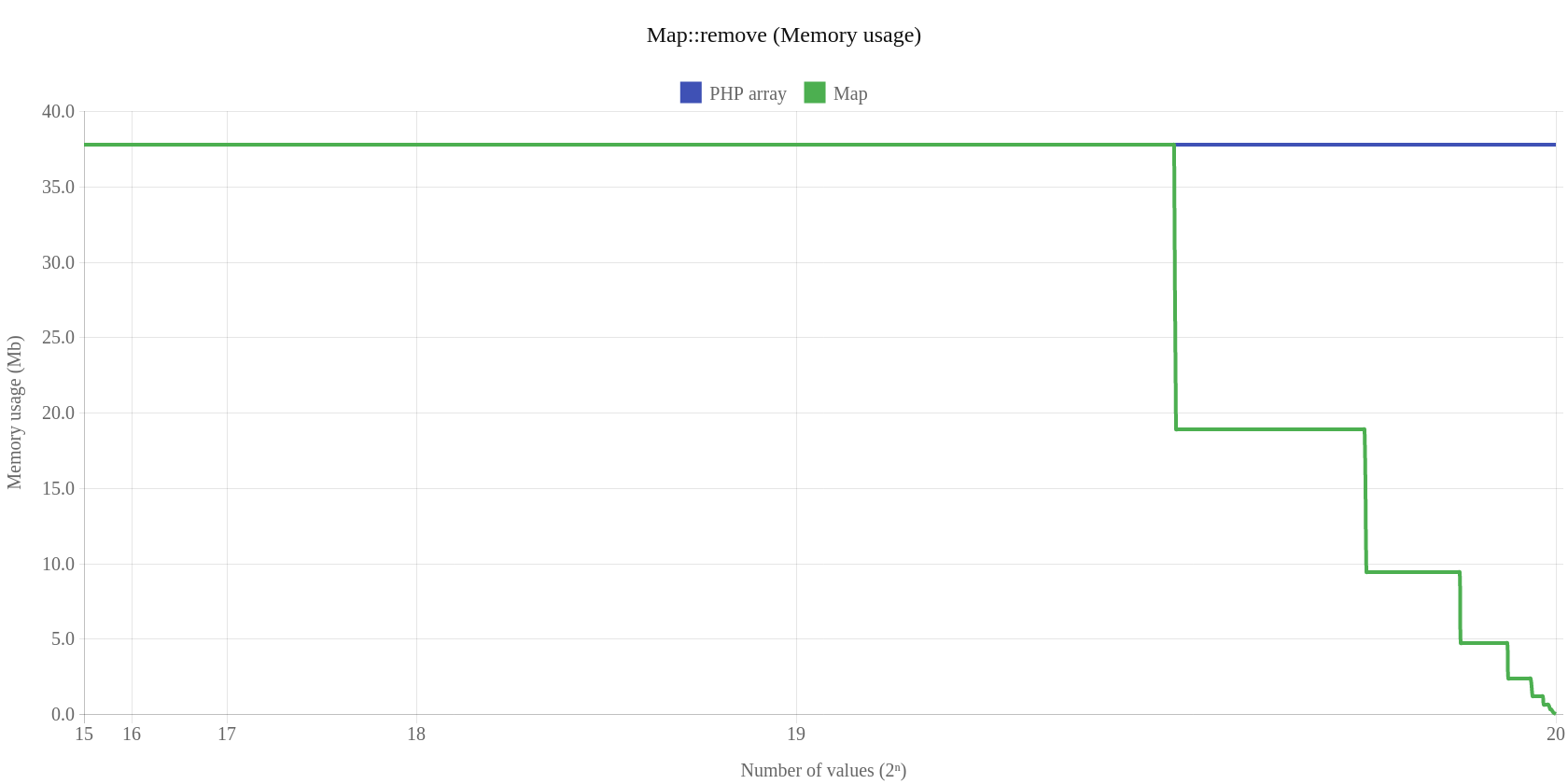
Na koniec porównanie klasy Set kontra natywny array_unique:
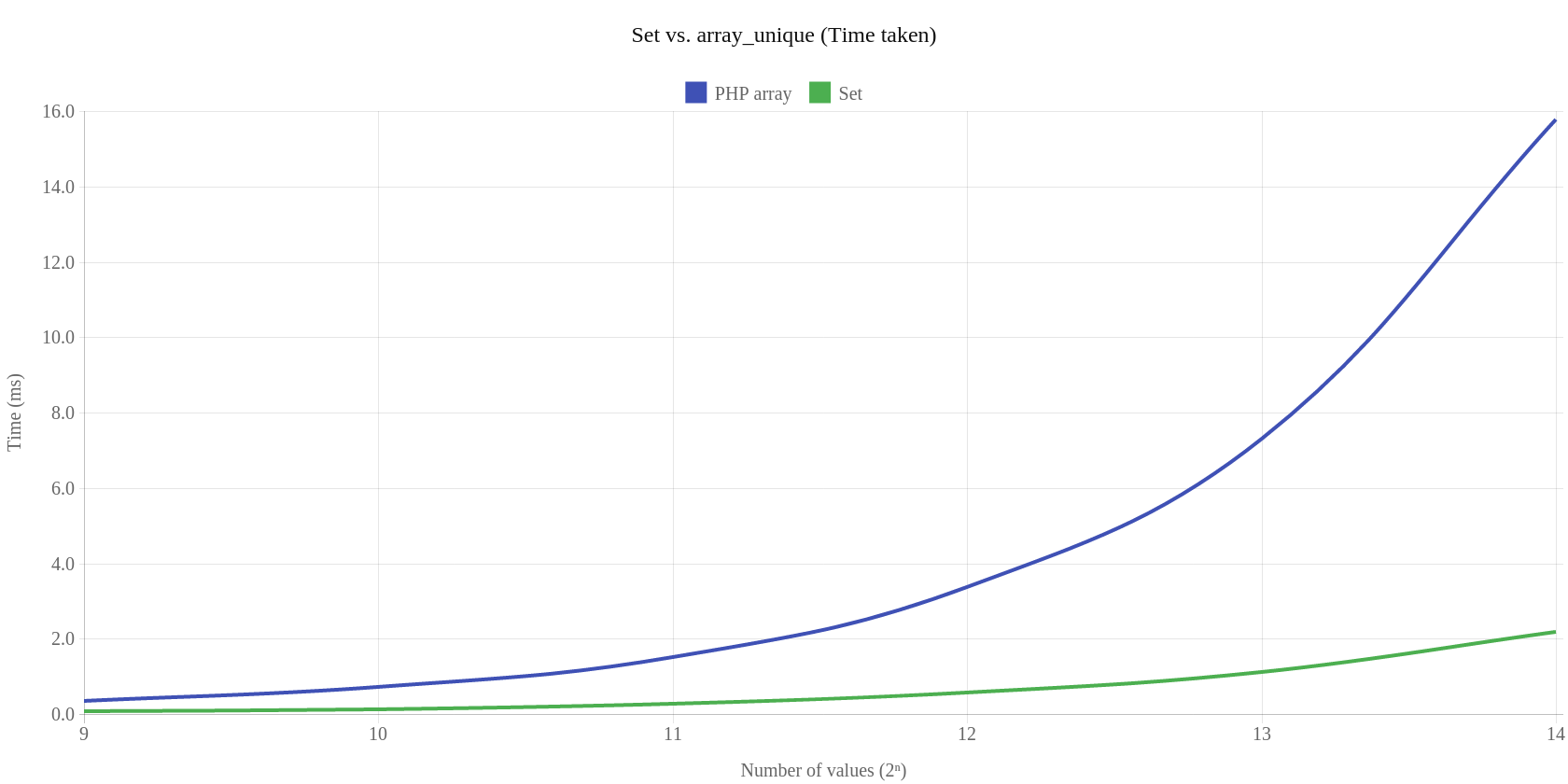
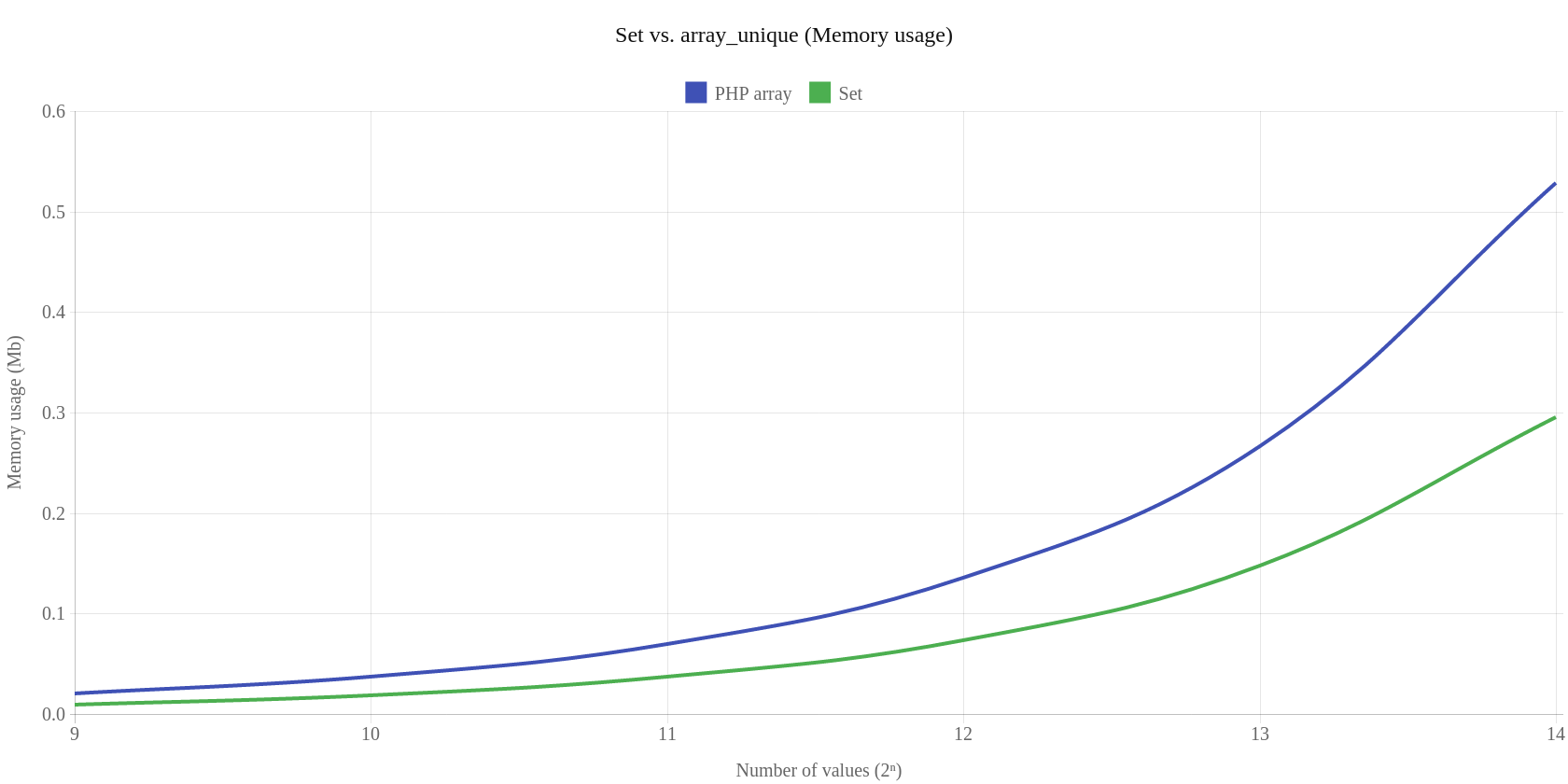
Zestaw testów
W chwili tworzenia tego wpisu, „php-ds” posiadało 2652 testów z 5509 asercjami. Przejście przez nie wszystkie na mojej maszynie trwało średnio 550ms i pochłaniało 14Mb pamięci. To naprawdę świetny wynik. Testy są bardzo czytelnie opisane i często zawierają dodatkowe komentarze. Na przykład poniżej wklejam pojedynczy test z wybranych testów klasy Deque:
public function testInsertAtBoundaryWithEqualOnBothSides()
{
$instance = $this->getInstance();
$instance->push(4, 5, 6);
$instance->unshift(1, 2, 3);
// [4, 5, 6, _, _, 1, 2, 3]
//
// Inserting at index 3 should choose to move either partition.
$instance->insert(3, 'x');
$this->assertToArray([1, 2, 3, 'x', 4, 5, 6], $instance);
}
Reasumując …
Mam nadzieję, że zaciekawiłem Was tym wpisem. Ja osobiście byłem pod olbrzymim wrażeniem dokładności i podejścia do tematu autora. Zresztą zmotywowało mnie to nowego wpisu (bo od jakiegoś czasu miałem problem z czasem i motywacją do pisania). Polecam zaznajomienie się z tym repozytorium, jego testami oraz możliwościami.
Trzeba jeszcze na zakończenie powiedzieć jedną rzecz: optymalizacja nie jest najważniejsza. PHP nie został stworzony pod kątem super wydajności, choć i tak nie jest źle. Pamiętajcie, że utrzymanie kodu i dbanie o jego jakość stoi na pierwszym miejscu (ale oczywiście to zależy).
P.S.
Ja osobiście zamierzam wykorzystać to rozszerzenie do mojego najnowszego projektu o którym już wkrótce będę intensywnie pisał.
Zdjęcie z wpisu: Flickr.
Entuzjasta programowania. Z zawodu web developer. Pragmatyk. Od jakiegoś czasu również przedsiębiorca. Racjonalista. W wolnych chwilach biega i bloguje. Miłośnik gier i grywalizacji. Więcej na jego temat znajdziesz w zakładce „O mnie” tego bloga.