
Daj się poznać 2016 – podsumowanie
 Konkurs „Daj się poznać” z dniem dzisiejszym dobiega końca. Oto krótkie podsumowanie co udało się mi się w tym czasie zrobić.
Konkurs „Daj się poznać” z dniem dzisiejszym dobiega końca. Oto krótkie podsumowanie co udało się mi się w tym czasie zrobić.
Biblioteka PHP-ML
https://github.com/php-ai/php-ml
Machine Learning w PHP. Przykładowe użycie algorytmu k najbliższych sąsiadów (k nearest neighbours):
use Phpml\Classification\KNearestNeighbors;
$samples = [[1, 3], [1, 4], [2, 4], [3, 1], [4, 1], [4, 2]];
$labels = ['a', 'a', 'a', 'b', 'b', 'b'];
$classifier = new KNearestNeighbors();
$classifier->train($samples, $labels);
$classifier->predict([3, 2]);
// return 'b'
To tylko prosty przykład wykorzystania. Najlepszym sposobem na pokazanie ilości prac będzie spis treści dokumentacji. W środku są liczne przykłady kodu i wyjaśnienia:
- Classification
- Regression
- Clustering
- Metric
- Cross Validation
- Preprocessing
- Feature Extraction
- Datasets
- Math
Wpisy na blogu
W czasie trwania konkursu udało mi się wyprodukować 20 wpisów (podsumowanie będzie 21):

Daj Się Poznać 2016 – zaczynamy
Krótko o tym czym jest konkurs „Daj Się Poznać”. Dlaczego biorę w nim udział, z czym to się wiąże i jak wpłynie na mojego bloga.
Wstęp do Machine Learning
Krótki wstęp do tematu uczenia się maszyn zwanego popularnie Machine Learning. Jakie problemy stara się rozwiązać oraz przykładowe zastosowania które zostały już wdrożone w codziennym życiu.

Algorytm k-średnich – uczenie nienadzorowane
Algorytm k-średnich (z ang. k-means) inaczej zwany również algorytmem centroidów, służy do podziału danych wejściowych na z góry założoną liczbę klas. Jest to jeden z algorytmów stosowany w klasteryzacji (grupowaniu) i jest częścią uczenia nienadzorowanego w Machine Learning.

Ogólnodostępne zbiory danych do Machine Learningu
Tak się składa, że dane i odpowiedzi jakie chcemy z nich wyciągnąć, to dwie najważniejsze rzeczy, które każdy specjalista od ML (zwany data scientist) musi posiadać, aby móc wykonywać swoją pracę. W tym wpisie przygotowałem krótki przewodnik po najpopularniejszych otwartych i ciekawych zbiorach danych.
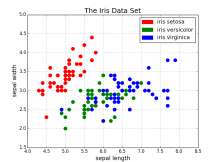
Wydajność PHP i Machine Learning
W tym krótkim wpisie sprawdzimy, czy pod kątem wydajności, PHP nadaje się do Machine Learningu.

Postępy w pracy nad PHP-ML
Krótkie podsumowanie pierwszych dwóch tygodni prac nad biblioteką do Machine Learningu.

Publikacja własnej biblioteki PHP z użyciem GitHub i Composer
Jak w szybki i prosty sposób udostępnić światu własny kawałek kodu i stać się kontrybutorem w świecie Open Source.
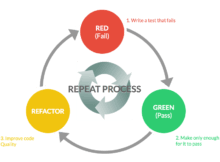
Red Green Refactor – testy jednostkowe
Praktyczny przykład pisania testów jednostkowych z wykorzystaniem metody „Red Green Refactor”.

Ciągła integracja i Travis CI
W tym wpisie odpowiemy na pytania: co to jest ciągła integracja oraz jak wykonywać ją sprawnie z pomocą usługi Travis CI.

PHP-ML – prac ciąg dalszy
Kolejne dwa tygodnie konkursu „Daj się poznać” za nami. Sprawdźmy co udało się dokonać w kwestii rozwoju biblioteki PHP-ML.
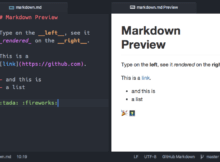
Markdown – tworzenie dokumentacji projektu
Pierwszy post z serii wpisów na temat tworzenia i prowadzenia dokumentacji projektów. Skupimy się w nim na popularnym języku znaczników Markdown.

Dokumentacja projektu – pragmatyczne README.md
Zaczynasz tworzyć lub rozwijać własną bibliotekę ? Uczestniczysz w projekcie open source ? Przeczytaj jak sprawnie i dobrze stworzyć pierwszy opisowy plik README.md, który będzie zalążkiem Twojej przyszłej dokumentacji.

Dokumentacja projektu – podejście kompleksowe
Wpis zamykający krótką serię dotyczącą dokumentacji projektu. W poście tym omówię co powinna zawierać dobra dokumentacja. Dodatkowo przedstawię generowanie i hostowanie dokumentacji z wykorzystaniem bezpłatnej usługi Read the Docs. Zapraszam.

Code Coverage w testach jednostkowych
Parę informacji na temat Code Coverage w testach jednostkowych. Co oznaczają poszczególne metryki i jak je interpretować. Całość głównie pod kątem PHPUnit.
Generowanie raportu Code Coverage z PHPUnit
Krótki manual jak wygenerować raport Code Coverage używając PHPUnita. W tekście znajduje się również link do przykładowego raportu wygenerowanego dla biblioteki PHP-ML.
Uzupełnianie brakujących wartości – PHP-ML
Z różnych powodów, wiele zestawów danych ze świata rzeczywistego, zawiera brakujących wartości, często oznaczone jako puste pola, nulle lub inne symbole.

Normalizacja danych – PHP-ML
Normalizacja to proces skalowania pojedynczych próbek w celu otrzymania małego, specyficznego przedziału. Przykładowo przekształcamy dane wejściowe w taki sposób, aby mieściły się w przedziale [-1, 1] lub [0, 1].

Walidacja krzyżowa – RandomSplit – PHP-ML
Sprawdzian krzyżowy (z ang. cross-validation) to technika polegająca na podziale kolekcji danych wejściowych na co najmniej dwa zbiory: uczący i testowy. W ten sposób można zweryfikować czy wyuczony model będzie dobrze działał na wcześniej nie widzianych danych. Walidacja krzyżowa zapobiega również przetrenowaniu (overfitting) modelu.

Ekstrakcja danych – tokenizacja tekstu – PHP-ML
Analiza tekstu jest jednym z głównych poligonów dla zastosowań algorytmów uczenia maszynowego. Jednak surowe dane tekstowe (czyli sekwencja symboli) nie mogą być poddawane bezpośrednio pod działanie algorytmów jak większość liczbowych wektorów o stałej wielkości.

Humbug – testy mutacyjne w PHP
Testy mutacyjne to narzędzie służące do analizy jakości testów jednostkowych i kodu źródłowego. Polegają one na wprowadzaniu małych zmian (mutacji) w kodzie źródłowym, a następnie sprawdzaniu, czy wpłynęły one na wyników testów (czy przestały przechodzić). Mutacje, które przetrwały (nie zostały wykryte) są potencjalnymi błędami, które nie zostałyby wykryte przez testy.
Postscriptum
Jestem mega zadowolony z tego co udało mi się zrobić i choć na końcu nie obyło się bez trudności to dotarłem szczęśliwie do końca.
Na przyszłość polecam Wam wszystkim takie inicjatywy i udział w nich bo dają dużą porcję wiedzy, motywacji i inspiracji.
Mogę śmiało powiedzieć, że najprzyjemniejszym momentem było wykorzystanie przez Mariusz Gila (@mariuszgil) fragmentu biblioteki PHP-ML w czasie jego prezentacji pt. „Holistic approach to machine learning”, która odbyła się w Bielsku-Białej na WeBB MeetUp. Dzięki Mariusz !
P.S. 2
Podsumowanie miało być dłuższe, pełne ochów i achów, dogłębnych przemyśleń i innych podobnych rzeczy, ale brakło mi czasu. Musi Wam wystarczyć to co jest 🙂 Jak tylko uda mi się poukładać parę spraw, to postaram się zrekompensować te krótkie wpisy i stworzyć kilka „grubszych” postów.
Entuzjasta programowania. Z zawodu web developer. Pragmatyk. Od jakiegoś czasu również przedsiębiorca. Racjonalista. W wolnych chwilach biega i bloguje. Miłośnik gier i grywalizacji. Więcej na jego temat znajdziesz w zakładce „O mnie” tego bloga.



